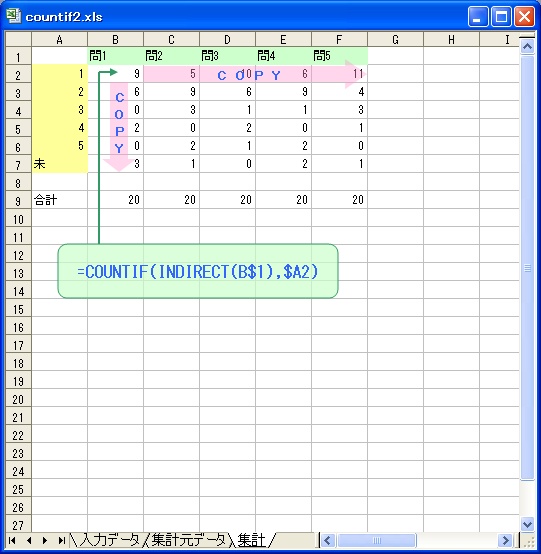
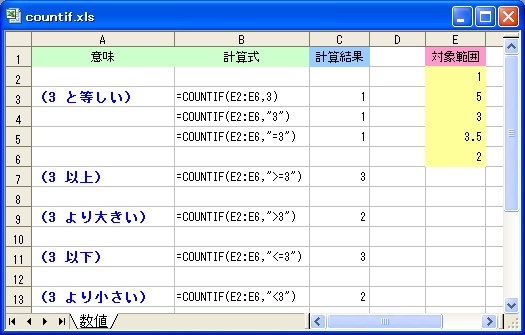
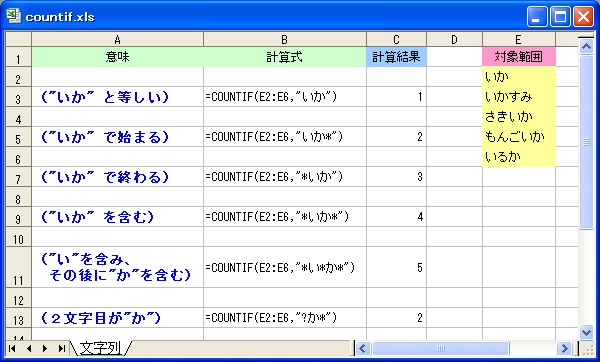
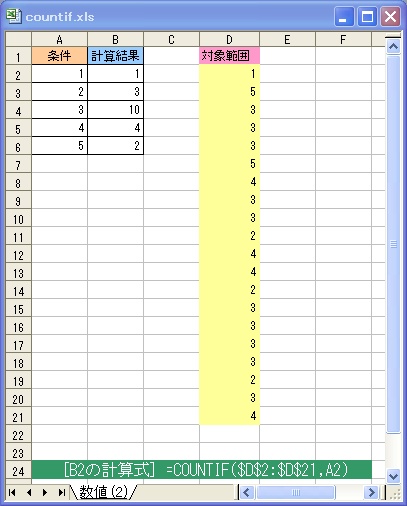
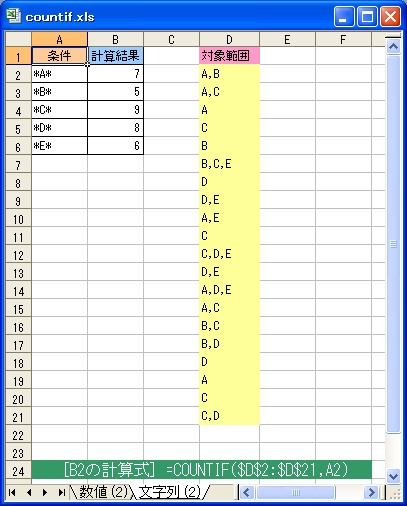
[書式] COUNTIF(<対象範囲>,<条件>)
[機能] <対象範囲> のセルのうち、<条件> に一致するセルの個数をカウントします。
| <対象範囲> | カウントしたいセル範囲を指定します。 |
| <条件> | 条件を、数値、文字列、式のいずれかで指定します。 |
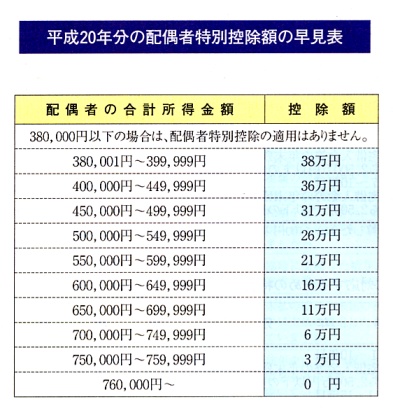
●●● 統計関数ではありますが ●●●
COUNTIF関数は、「統計関数」というカテゴリに分類されています。
でもだからと言って
「COUNTIF関数 = 集計と統計のための関数」
とは限りません。もっと幅広く、別の用途にも活用できます。
たとえば、特に便利なのが重複データのチェック。
名簿の重複、商品登録の重複など、ワークシート上で長くデータを運用していると、さまざまな
ダブリを生じてしまうことがあります。そんなダブリを調べたり、排除するような用途にも
COUNTIF関数は活用できます。
●●● 重複があるかどうかを調べる ●●●
それでは、まず重複があるかどうかを調べる方法です。
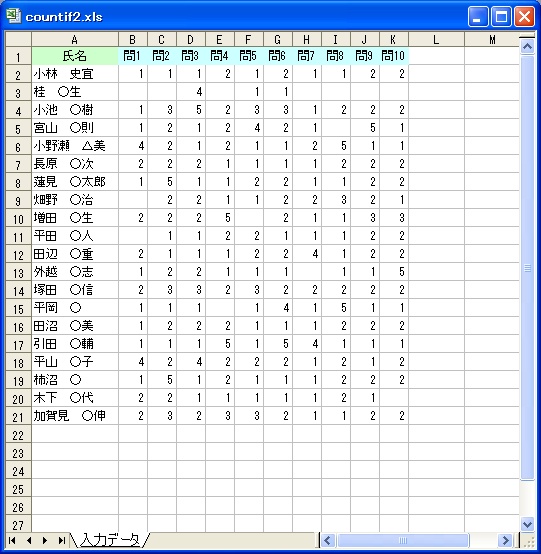
この例題は、氏名と郵便番号だけからなるシンプルな名簿です。この表から、氏名が重複して
いる行を見つけてみましょう。
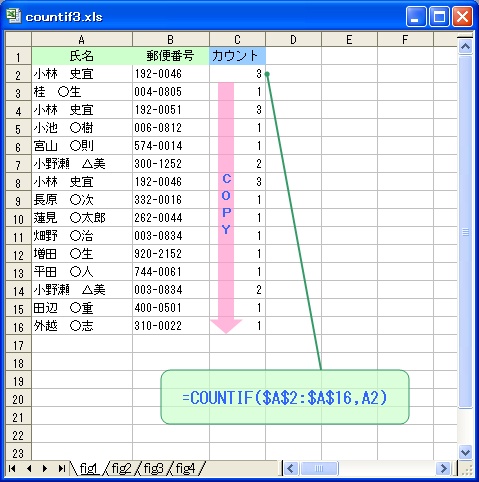
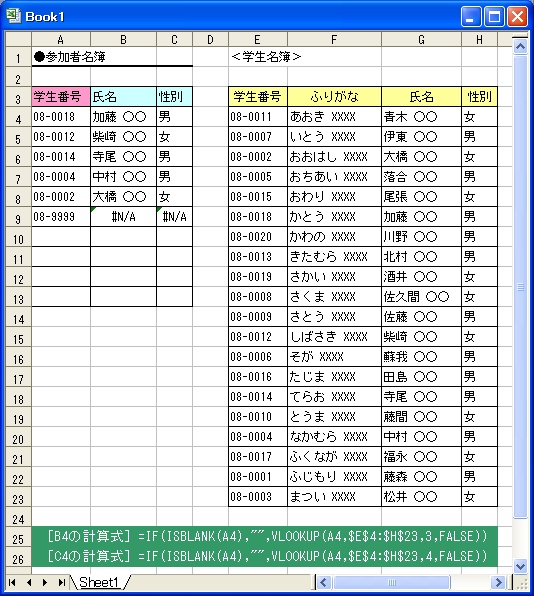
(1) カウント用に C列を準備する。
(2) セルC2 に、次の計算式を入力する。
=COUNTIF($A$2:$A$16,A2)
(3) セルC2 の計算式を セルC3~C16 の範囲にコピーする。
セルC2 に入力した計算式は、
「セルA2~A16 の範囲に、セルA2 の氏名が何個あるか」
を求めるものです。
そして、<対象範囲> の部分は絶対参照にしています。こうすれば、下方向にコピーするだけ
で、それぞれの氏名の個数が正しく計算されます。
この計算結果で、値が 2 以上のものは氏名が重複しているということが判りますね。
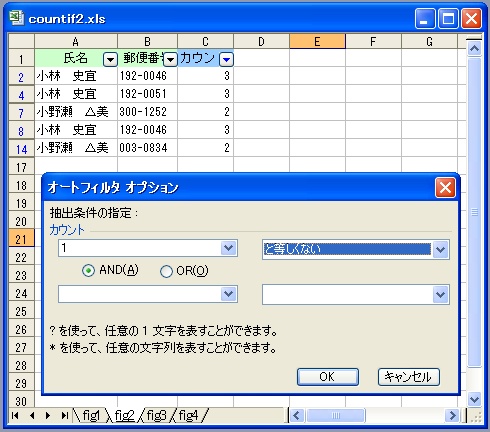
さらに、下図のようにオートフィルタを利用して絞り込めば、重複のあるデータだけを参照する
ことができます。
(1) [データ]メニューから [フィルタ]-[オートフィルタ] を実行。
(2) C列の [▼] をクリックし、オプションを選択。
(3) 「1」 と 「等しくない」 という条件を指定し、[OK] をクリック。
この例題はたったの15件のデータでしたが、数百件、数千件の時には、とても便利な方法です。
また重複データが多い場合、並べ替えなどの機能も併用すると、作業がやりやすくなります。
●●● 重複を取り除く ●●●
上の例題は、重複しているデータを全件とも表示するためのものでした。
次に、重複行を取り除いてしまう方法について見ていきましょう。
(1) [データ]メニューから [フィルタ]-[オートフィルタ] を選択してオートフィルタを解除。
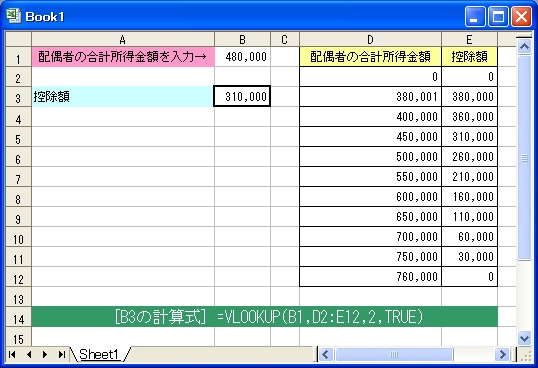
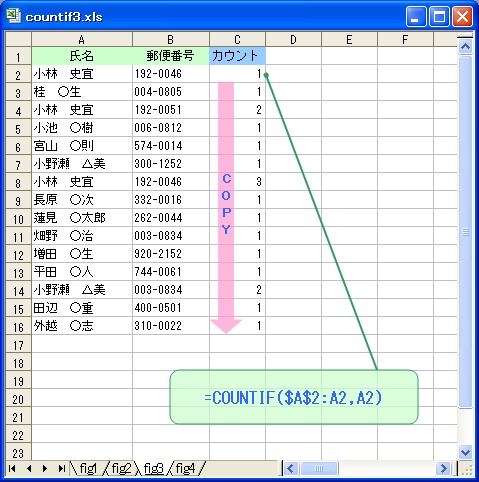
(2) セルC2 の計算式を、次のように変更する。
=COUNTIF($A$2:A2,A2)
(3) セルC2 の計算式を セルC3~C16 の範囲にコピーする。
この新しい計算式のポイントは <対象範囲> です。
セルA2~A2 を指定していますが、片方が絶対参照、もう一方が相対参照になっています。
絶対参照の方はコピーによって変化しませんが、相対参照の方は下方向へコピーすることで
A3 , A4 , A5 ・・・
と、変化していきます。
その結果、それぞれの計算式は、
セルC2 =COUNTIF($A$2:A2,A2)
セルC3 =COUNTIF($A$2:A3,A3)
セルC4 =COUNTIF($A$2:A4,A4)・
・
・となります。
つまり、この計算式の意味は、
「自分自身の行から上の範囲に、同じ氏名が何個あるか」
というものなのです。
重複がある場合には、1番目のデータは 1 、最初の重複データは 2 、その次の重複は 3 という
計算結果になります。
今度はオートフィルタで、1 だけを表示するように絞り込めば、2番目以降が排除されて、重複の
ないリストを見ることができます。
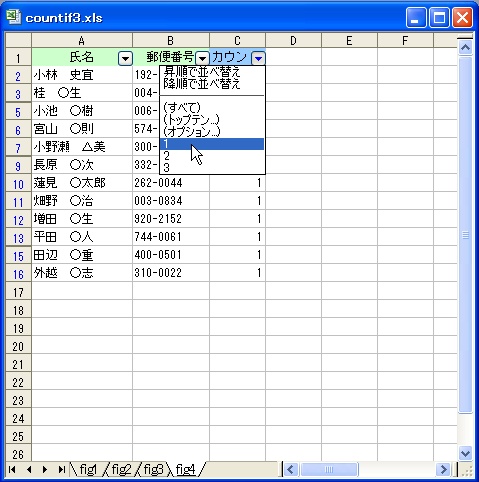
(1) [データ]メニューから [フィルタ]-[オートフィルタ] を実行。
(2) C列の [▼] をクリックし、「1」を選択。
さて、しかしこのシートは、実際に重複行がなくなったわけではありません。見えなくなっている
だけで、シート上には存在しています。
本当に重複を排除した表を作成するには、もうひと手間が必要です。オートフィルタによって絞り
込まれた状態の表をコピーして、新しいシートに貼り付ける必要があります。
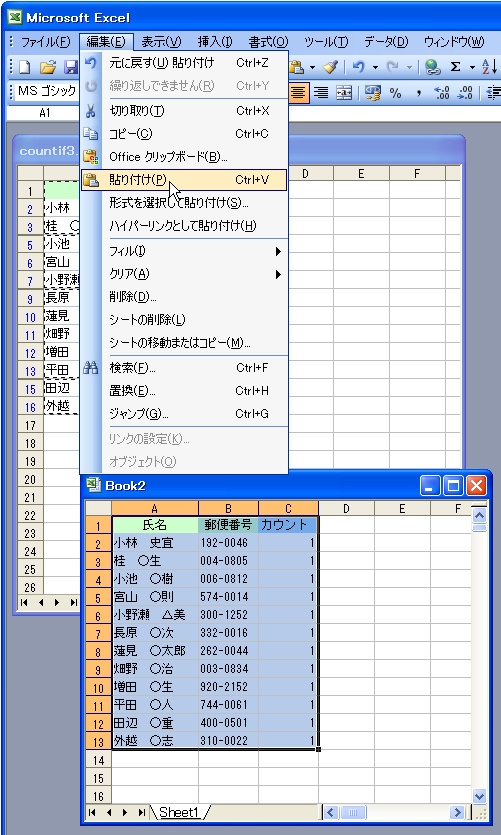
(1) セルA1~C16 を選択。
(2) [編集]メニューから[コピー]を実行。
(3) 新規ブックを開く。
(4) [編集]メニューから[貼り付け]を実行。
これで、重複のない新しい表ができあがりました。